(NOTE: this first appeared on Substack here)
Starting this up again. Since I last wrote, I took an RL and math-for-ML-ish class (+ did research in our RL lab) so I’ve gotten my hands dirtier with all of this and have actually played with PyTorch (and JAX) my self. However, I’m still certainly getting up to speed on some of the more ‘applied’ or ‘deployed’ parts of this, and the fundamentals still feel useful!
Lesson 3 (chapter 4) in the book is mostly just a summary of ML fundamentals: stochastic gradient descent, backpropagation, loss functions, mean-squared error, etc. Most of this stuff felt pretty familiar so I skimmed a lot of it and watched the video on 2x. The notebooks for this lesson were also pretty much “intro to PyTorch” and general stuff with tensors. I sped through this as well.
In essence, most functions are first implemented in Python, and then you’re shown the PyTorch implementation after—for example, first creating your own linear1
layer, and then using nn.Linear


They generally encourage you to use the concepts in a chapter and apply them to another dataset. I made some pretty minor changes because we’ve already built this before—I used MNIST instead of MNIST_SAMPLE, and did twos and fours instead of threes and sevens. I also made the loops more minimal, i.e. get rid of lots of the intermediate steps from the notebook for training. You can see my notebook here, but the gist is that the loop works, even if it’s learning pretty slowly:
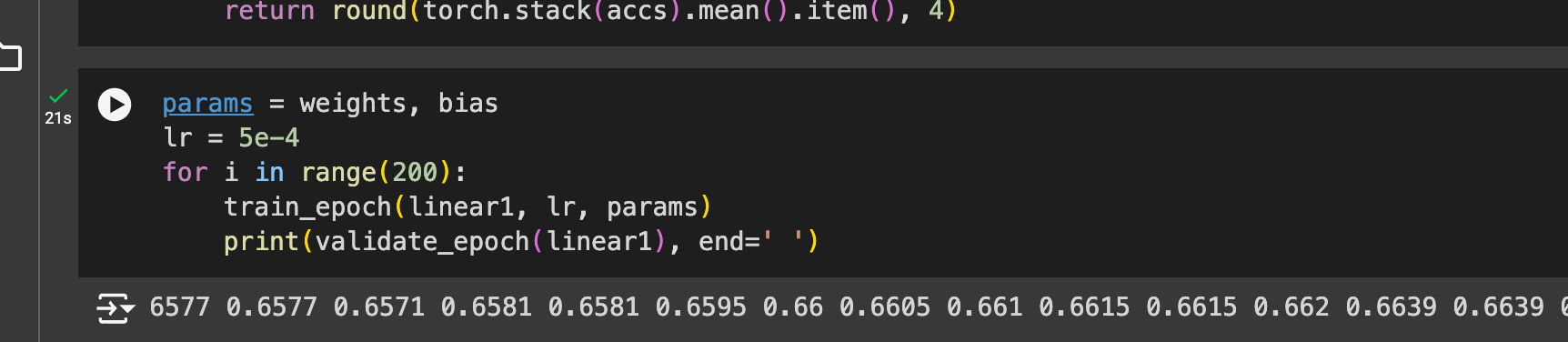
it works quite quickly when we use more of PyTorch and fast.ai’s functionality:
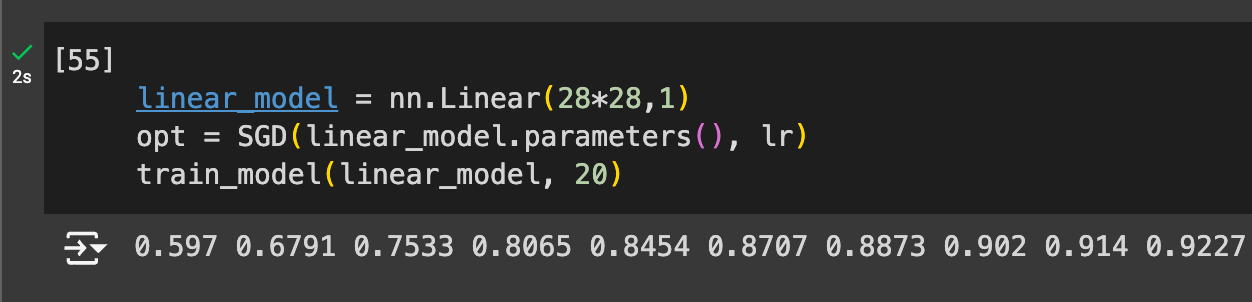
A meta-learning note: I left this chapter half-completed for several months and it made it way harder to get started. Better to not start than go halfway through. NOTE: here’s my notebook for all of the NN foundations stuff.
Here’s the questions for the chapter:
- ✅ How is a grayscale image represented on a computer? How about a color image?
2d array of pixel intensity values (either 0-1 or 0-255). For a color image, this, but three channels (RGB)
- ✅ How are the files and folders in the
MNIST_SAMPLEdataset structured? Why?train/ and test/. Basically, they are structured so that you train and evaluate with different data, rather than training on (and inevitably memorizing) the test set (NIT: train/ and valid/)
- ✅ Explain how the "pixel similarity" approach to classifying digits works.
Take all instances, of, say, "3", average their pixel values at every individual square (in this case: we are only dealing with 28x28 images), and then, when trying to determine another digit, subtract the pixel value of the image you are evaluating from the average "3" - see if this difference is larger or smaller than the average for "7"
- ✅ What is a list comprehension? Create one now that selects odd numbers from a list and doubles them.
Python functionality to process each element of an array in shorthand. [2*num for num if num % 2 == 1] i think is right
- ✅ What is a "rank-3 tensor"?
Meaning a tensor with three dimensions.
- ✅ What is the difference between tensor rank and shape? How do you get the rank from the shape?
Tensor rank is the number of dimensions, and shape is all of the dimensions. For example, shape might be (28, 28, 200) and rank here would be 3.
- ✅ What are RMSE and L1 norm?
RMSE = (R?) means-squared error, taking the difference between the current number and mean and squaring it. L1 norm, I believe, is just subtracting the mean and taking the absolute value.
- ✅ How can you apply a calculation on thousands of numbers at once, many thousands of times faster than a Python loop?
Using numpy or PyTorch computations, which run the actual computations in optimized C.
- ✅ Create a 3×3 tensor or array containing the numbers from 1 to 9. Double it. Select the bottom-right four numbers.
this_tensor = torch.arange(1,9, step=1).reshape((3,3)) (NIT: use view)
this_tensor = this_tensor * 2
this_tensor[:1][:1]
- ✅ What is broadcasting?
I believe it's where an operation that is written out once in code is applied to many other cells? I.e. write it once and it applies more generally. (NIT: sorta: tensors with smaller rank are expanded)
- ✅ Are metrics generally calculated using the training set, or the validation set? Why?
Calculated on the validation set not the training set. The model could memorize values if we evaluated on the training set.
- ✅ What is SGD?
Stochastic gradient descent. We use it to move in the correct direction, based on the derivative of the loss function.
- ✅ Why does SGD use mini-batches?
Calculating loss for each training example is too time-intensive and doesn't give the GPU enough things to do together. (NIT: also, need multiple examples to calc loss function)
- ✅ What are the seven steps in SGD for machine learning?
this is a weird numbered task, let's see
1. make a prediction from model
2. evaluate the prediction based on the loss function
3. calculate the gradients of the loss function
4. update the weights based on the learning rate and the gradient
5. reset the gradients
missing another two?
CLOSE ENOUGH: missing initialize parameters, last stop is "stop"
- ✅ How do we initialize the weights in a model?
Randomly!
- ✅ What is "loss"?
I II I IL LOL. no seriously though, how much the model's predictions differ from ground truth predictions in the validation set.
- ✅ Why can't we always use a high learning rate?
it's likely we'll bounce back and forth between extremes too much - the weights will not end up converging
- ❌ What is a "gradient"?
the second derivative! the direction the loss's increase is moving in, I believe - actually just the derivative
- ✅ Do you need to know how to calculate gradients yourself?
nope!
- ✅ Why can't we use accuracy as a loss function?
we need the loss function to be differentiable so we know which way to move!
- ✅ Draw the sigmoid function. What is special about its shape?
not going to draw it, but looks S-like and significance is that it is always increasing and will make high and low numbers move to (0,1)
- ✅ What is the difference between a loss function and a metric?
A metric would be how well the model performs, while a loss function, being based on metrics, gives us something that indicates the direction we need to change to improve (NIT: metrics are human understandable, loss is machine-understandable)
- ✅ What is the function to calculate new weights using a learning rate?
Don't remember what we called it, but it's stepping the loop, maybe train_step or similar (NIT: the optimizer step function)
- ✅ What does the
DataLoaderclass do?Makes a set of training data iterable, or handles the dependent and independent variables / making them into tuples that PyTorch will play nicely with
- ✅ Write pseudocode showing the basic steps taken in each epoch for SGD.
this is the same as #14, I believe?
- ✅ Create a function that, if passed two arguments
[1,2,3,4]and'abcd', returns[(1, 'a'), (2, 'b'), (3, 'c'), (4, 'd')]. What is special about that output data structure?list = []
for index in range(len(a)):
list.push(a[index], b[index]
surely a better way to do this but this is quick (NIT: this probably works, but list(zip(a,b)) works!
- ✅ What does
viewdo in PyTorch?I believe: reshapes a tensor?
- ✅ What are the "bias" parameters in a neural network? Why do we need them?
For linear layers, we can think of the weights, in y = mx + b, as m, and the biases as the y-intercept / amount we are changing independently, or b. (NIT: helps if input is 0)
- ✅ What does the
@operator do in Python?Matrix multiplication!
- ✅ What does the
backwardmethod do?calculates the gradients
- ✅ Why do we have to zero the gradients?
PyTorch otherwise will add the gradients to the one before
- ✅ What information do we have to pass to
Learner?the architecture, the learning rate, the optimizer? (NIT: loss fun, dataloaders, metrics)
- ❌ Show Python or pseudocode for the basic steps of a training loop.
I'm pretty sure this is #14 as well - need calc grad and to call train_epoch a bunch - fairly self-explanatory though
- ❌ W What is "ReLU"? Draw a plot of it for values from
2to+2.stops FN from going to 0, i.e. would be 0 for all values <0 and 1 for all values >1 i believe - relu just gets rid of negatives
- ❌ W What is an "activation function"?
Don't remember! NOTE: provides non-linearity, because otherwise layers are just equivalent to y = mx + b - decoupels rest of the layers
- ✅ What's the difference between
F.reluandnn.ReLU?one is in Torch and one is Fast.ai? NIT: one is python
- ✅ The universal approximation theorem shows that any function can be approximated as closely as needed using just one nonlinearity. So why do we normally use more?
way more accurate? or need less precision? NIT: need fewer paramters