Here we are, the main event! Finally, onto diffusion models!
This was, luckily, just as interesting as I was hoping, and very easy to move through.
The lesson has no book chapters, and on quick glance it seems like none of the future lessons do either. They warn pretty strongly that much of the content soon be outdated, because of the pace of research, but that many of the concepts in the lessons are fairly foundational to how neural nets work.
My sense also is that I'm going to start to read a lot more papers. I read some ML research while in my school's lab, but most of this graphics stuff is new to me. This week, I read the U-Net paper, which I felt I mostly grokked, but likely need to revisit further into the course. A personal note that:
- I need to read papers with access to Google/ChatGPT to get the most out of them and
- I should set up a Zotero library to keep track of these! I will!
Anyways, Jeremy's lesson was pretty interesting even just from the POV of someone who has casually used diffusion models before. In particular, it was interesting to see how random seeds work, and to see the "insides" of the model. Basically: it was neat to see that diffusion is a gradual process, and that you can look at a model's results after different inference steps. (One of my instincts: there's probably some really interesting conceptual stuff you could do artistically, re only partially diffused models - or that this is extremely under-explored!)
Other stuff that's generally available in models was pretty interesting, like guidance scale, negative prompts, "strength" in image-to-image generation, and general stuff around fine-tuning. A friend's startup places people's faces into diffusion-generated images; it was interesting to see that this was (likely) done with textual inversion, where an obscure concept is trained into the model. One of the weirder things to think about was that you could fine tune with an image captioning model - or, basically, that you could feed training data to the model using another model! Pretty cool.
In working through this course, I'm most excited about learning how to read/implement papers, and try new things — Jeremy mentions that this stuff gets to postgrad level, and it's pretty neat there's resources to get to the so-called 'frontier of knowledge' here!
I'm pretty compelled by the idea of doing more of this, but I sense I'm nearing the point where I could risk hitting "tutorial hell:" I'm sure watching the Andrej Karpathy videos would help me understand backpropagation better (and maybe I'll watch some of them), but at a certain point, I think the best way to learn is through implementation and figuring out what I'm missing. Seems like there's tons of stories online of people who keep doing Massive Open Online Courses without actually applying what they're doing.
This said: I got a ton many years ago out of doing freeCodeCamp; I only got a lot out of it because freeCodeCamp gave me enough basics to reach escape velocity on my own, with projects and in work settings, and I think that's the same way to view all of the stuff here. Basically: 'just enough formal training' is the goal here. And: I tend to prefer self-paced / higher quality online stuff to traditional instruction, so this sort of 'formal / informal' course, I think, will be perfect :)
I need a case in which to implement this stuff: I've been working on a tool for storyboarding with image models. Many people asked for an ability to do consistent characters — I think I could pretty easily implement some of the training from the course to build this.
For my own use, I'm going to explain the broad process of how diffusion models work, at a high level, as explained in the video:
- We start with a U-Net. (NOTE: clarify?) that takes a somewhat noisy image and outputs the noise. By 'subtracting' the noise from the image, many times, we get something that looks like an un-noised image.
- We use a model called an "autoencoder". I thought this was incredibly conceptually interesting (I felt the same sort of wonder I did when learning about hash tables for the first time). There's two parts, an encoder and a decoder. Basically: the encoder shrinks an image down a ton, by doing stride-2 convolutions that lose data at each point, up until a very small point. Then, there's a decoder, essentially the inverse of the first, that scales that middle, small amount of data, into something resembling a whole image. It was neat to finally read about this — I implemented the encoder and decoder steps for Segment Anything 2 a few weeks ago. If you train a loss function on how similar the input and output are, you can train the network to, essentially, be an extremely efficient compressor! The middle step, the stuff between the encoder and decoder: these are called "latents" (Also, to note: we actually use a Variational Auto-Encoder)
- Let's use the U-Net to predict noise on the latents, because running the U-Net process is pretty computationally intensive. Basically: we can denoise something equivalent to a much smaller image, for speed.
- Are there ways we could make the U-Net better at predicting noise? One way to do this would be, in the case of numerical digits going in, to feed in the digits; surely this would make it a better predictor of noise, to know what digit went in. This, however, obviously doesn't scale: what about the endless number of concepts we'd need? What we'll do instead is use an embedding: we need some sort of third value to represent the concept that is in the image.
- Now, what if we don't want to go image to image, maybe we want to go text to image? What we could do here, instead, is to train a set of embeddings where text about a concept and an image of that concept will resolve to similar values. We can train this using a techniquee called CLIP: the CL stands for "contrastive loss". Basically, we can feed in a bunch of captioned images, and create embeddings such that the loss is very low for similar images and similar words. Eventually: multiplying the dot products of similar words and images will yield very high numbers.
- This is most of the process! Basically: text is fed in, an embedding is found that corresponds to the text, it goes through the encoding process to become small latents, noise is added, and then, progressively, the U-Net predicts the amount of noise, removes parts of it and and the decoder upscales it into a real image.
I feel decent but not perfect here, which I think is exactly the level of understanding to go for at this point: working knowledge, such that I feel pretty confident I could dive into implementation.
For notebooks, it seems like half of this notebook is used for Lesson 9 and the other half for Lesson 10. The parts for Lesson 9 I recreated in my own notebook here.
It was neat to have Stable Diffusion working in code, versus in Automatic1111 or something similar. For example, here's the CoLab diffusion result for "a 23 year old software engineer sitting at a desk in front of a compute rscreen"

As mentioned above, I was pretty interested in looking at the middle inference steps. Here's what it looks like at steps = [8, 16, 24, 32, 40, 48, 56, 64, 72, 80, 88, 96, 104, 112, 120, 128] (very very cool: I want to look more at this in the future!)

There's also stuff in the notebook for image to image. Here's an example with the photo I use on the cover of my site. Interesting some of the artifacting in the black square zone, but generally quite cool!
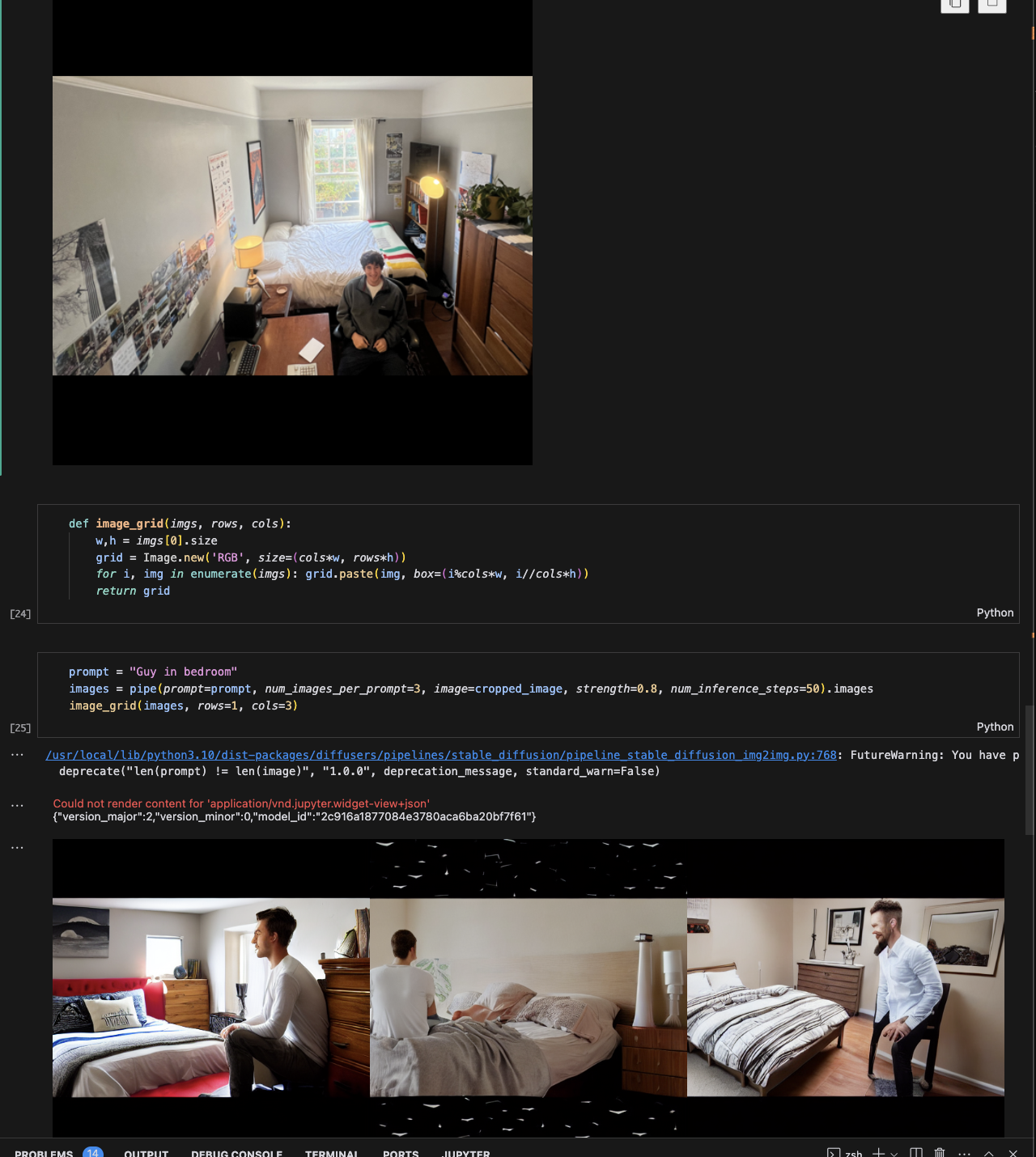
I tried this again using different guidance scales, g = [1.1,3,7,14] which was quite interesting:

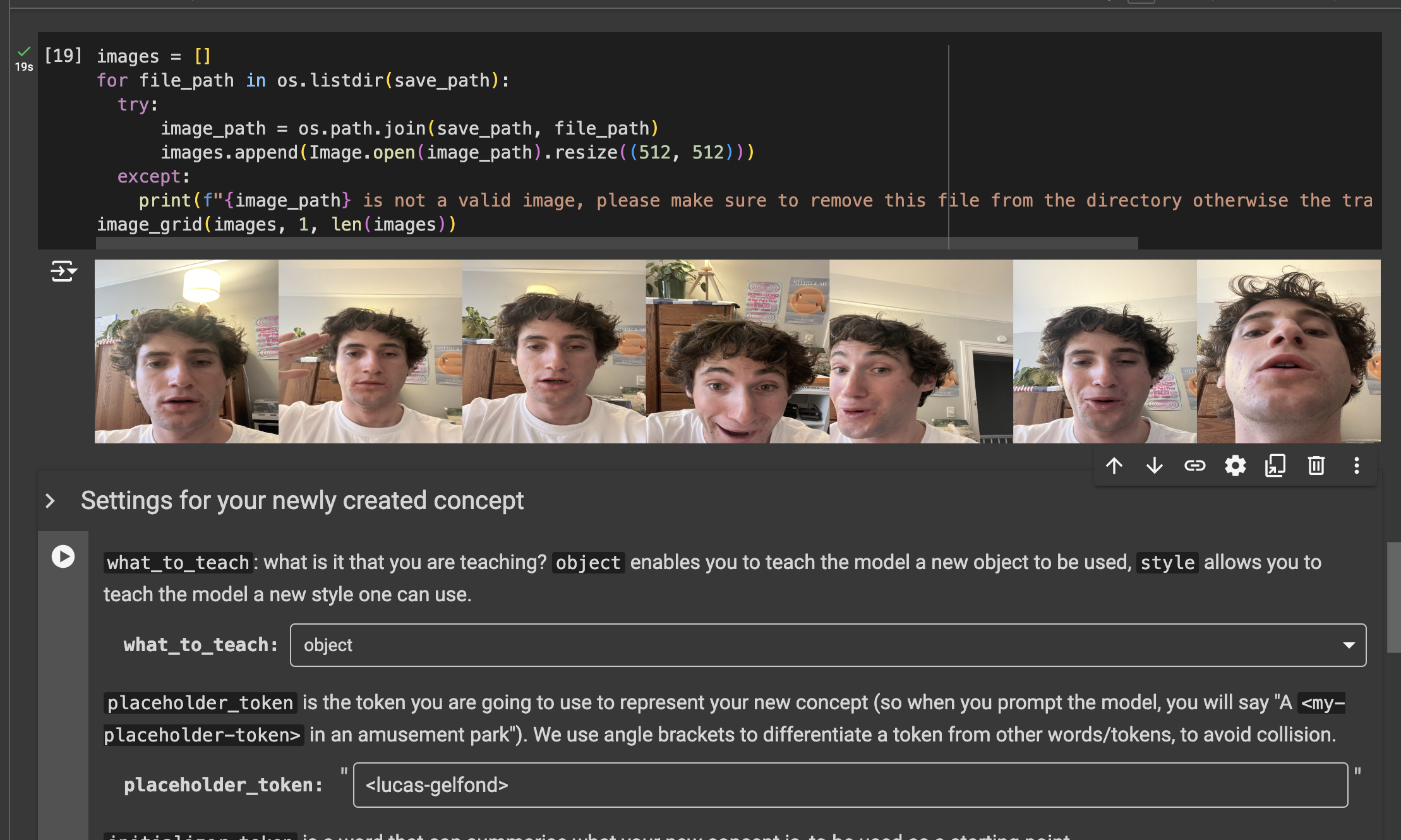
Perhaps my favorite part of the whole lesson was the Dreambooth part of hte notebook, where I used a process to fine tune a model on the concept <lucas-gelfond>. You can see the version of the dreambook notebook I used here
I fed it some images, and it actually really does look like me!
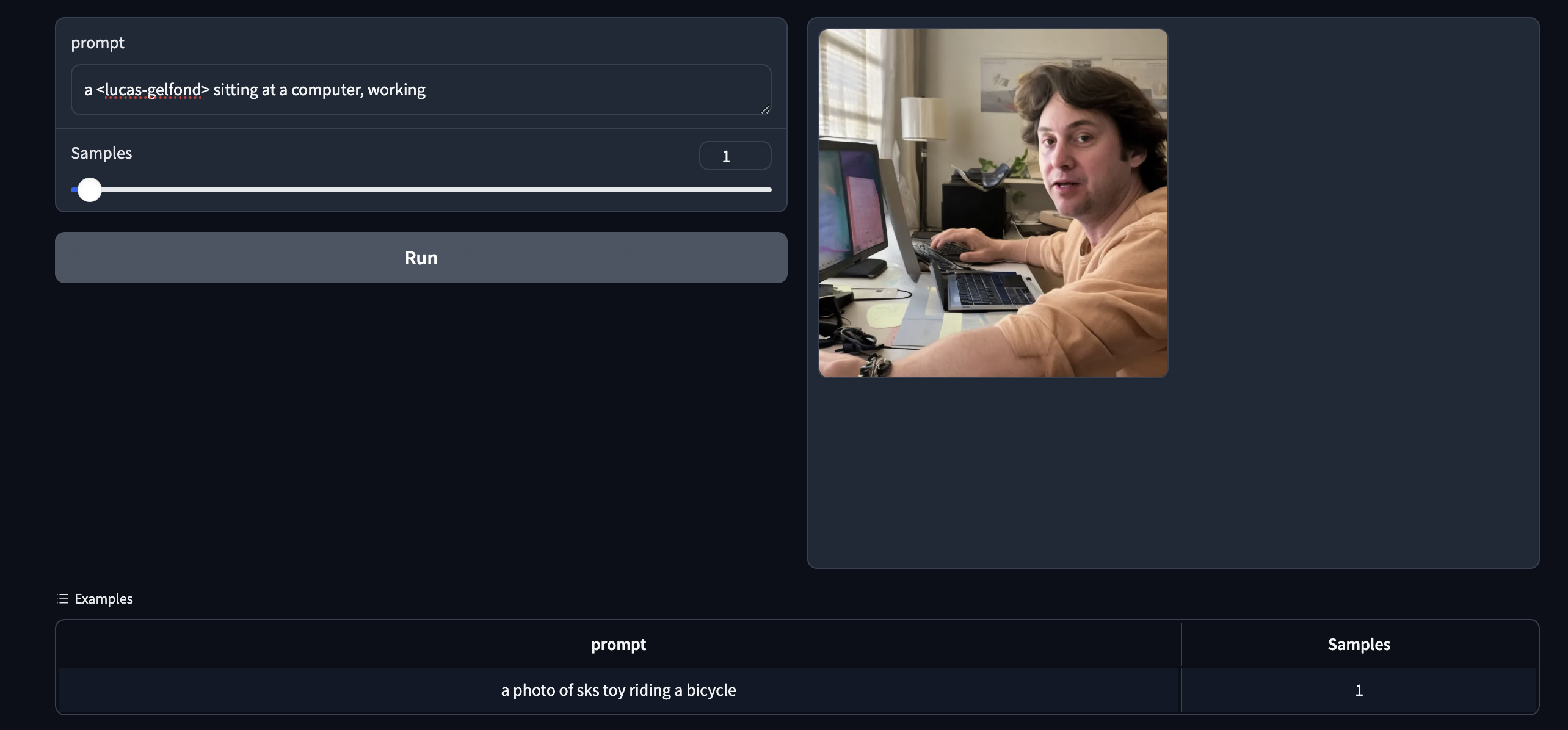
I uploaded this to the HuggingFace "library of concepts" which I thought was pretty funny.
Anyways, I'm really, really loving this, like, this is some of the most interesting stuff I've ever worked on hands down. Excited for more updates as I get further!
Stuff I want to follow up on:
- Jeremy's co-authored paper The Matrix Calculus You Need For Deep Learning. I only really got into math at the end of college (so no calc 3!), but I loved what I took, and this seems like a great way to pick up stuff that I might need.
- Reading the High Resolution Image Synthesis paper. It seems like Lesson 10 goes more into this, so this is after, for sure.
- Reading HuggingFace's The Annotated Diffusion Model and Lillian Weng's blogpost about it that I've seen cited a bunch.
- Reading the variational auto-encoder paper. We were working with a VAE, I believe, on the project I did in school, but I don't think I grokked enough of it. More soon!
Anyways: I'm really loving this. More soon!